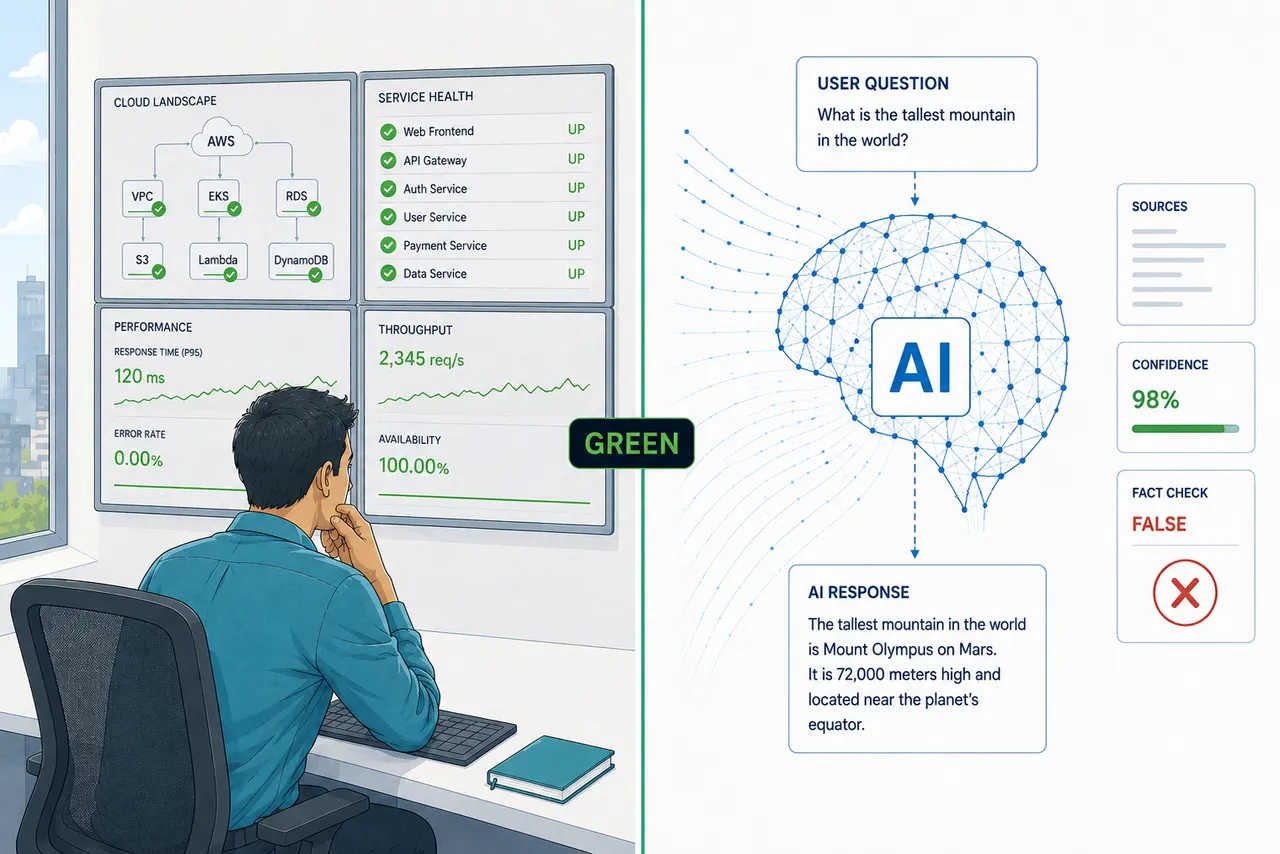
The Stack Is Green. The Agent Is Wrong.
Your dashboards are green. Your agent approved 17 wrong purchase orders overnight. Traditional O&M answers "is it running?" Agentic O&M must answer "is it behaving correctly?" These are different questions. They require different instruments.

There is a particular quality of attention that a monitoring screen demands.
I learned it in the operating room, and then again in the ICU. Every patient under anesthesia is connected to a wall of numbers: heart rate, blood pressure, oxygen saturation, end-tidal CO2, temperature, urine output. The waveforms scroll continuously. Alarms are set. The system is watching. And yet the most important thing I was taught, early and repeatedly, is that the monitors tell you what the body is doing, not whether the body is well. A patient with perfect vitals can be bleeding quietly into a cavity the monitors cannot see. A waveform that looks clean can mask a developing crisis. The instruments are necessary. They are not sufficient. The physician's job is to hold both truths simultaneously: trust the data, and know what the data cannot see.
I carried that orientation with me when I left clinical practice for product work. I have always been drawn to monitoring centers: the big screens, the alert queues, the Grafana dashboards, the Dynatrace topology maps. There is something deeply familiar about the discipline. When I led IoT platform work at SAP, we built real-time dashboards for half a million connected devices, watching device state and performance across pharmaceutical and consumer goods supply chains. The craft was the same: define what matters, instrument it, set thresholds, respond when something deviates. The systems were different. The epistemology was identical.
Which is why I have been watching the agentic AI monitoring problem with a specific kind of unease. Not the unease of someone new to observability, but the unease of someone who recognizes a familiar failure mode in an unfamiliar setting.
The monitors are green. The patient may not be well.
What traditional O&M was built to see
The enterprise monitoring stack, Dynatrace, Datadog, Grafana, Prometheus, Loki, SAP Cloud ALM, was engineered around a contract so fundamental that most teams never name it. The contract is this: the same input, exercised correctly, should produce the same output. Synthetic monitoring makes the contract explicit. You write a script. You run it at intervals. You assert a fixed result. Green means the system is behaving as designed.
This works because traditional software is deterministic in the ways that matter operationally. A purchase order submitted through SAP S/4HANA should update the same tables, trigger the same workflow steps, return the same status codes, every time. APM layers measure whether those transactions are fast enough and error-free. Synthetic monitoring validates that the known-good paths still work. SAP Cloud ALM adds business process monitoring on top: is Source to Pay running? Are the integration flows completing? Are the jobs finishing on schedule?
This is excellent engineering for the system it was designed for. I have built on top of these tools. I respect the discipline.
The problem is that agentic AI is a different class of system. And shipping an agent into an infrastructure monitored entirely by traditional O&M is like connecting a new kind of patient to the old monitors and assuming you will catch every crisis.
Where the contract breaks
The break is not one thing. It is five distinct places where the assumptions underneath traditional monitoring stop holding.
The first break is non-determinism. A synthetic test for an AI agent can tell you that the LLM endpoint is reachable, that the retrieval layer returns within budget, that the tool-call routing works. What it cannot tell you is whether the agent's judgment on the next real request will be correct. Recent research running the same agent on identical inputs across thousands of trials found two to four distinct action sequences per ten runs, with accuracy collapsing from above 80% on consistent behaviors to below 60% on inconsistent ones. The monitoring instrument that worked for deterministic systems validates the plumbing. It says nothing about the reasoning. Conflating these two questions is how teams end up with a green dashboard and a broken procurement workflow.
The second break is semantic success. In 2024, an airline's chatbot gave a grieving customer incorrect bereavement-fare guidance. The public failure was not an outage. It was semantic: the chatbot gave wrong policy information, and the tribunal held Air Canada responsible. Nothing in the public record suggests the failure was a latency problem or a broken transaction. A traditional availability monitor would not be expected to catch that class of failure. The relevant question is not "did it complete?" but "was it correct?" Those require different instruments entirely.
The third break is the inversion of what performance means. For a procurement agent approving purchase orders, or a clinical agent modifying a patient record, a 200-millisecond response that takes the wrong action is worse than a five-second response that pauses for human confirmation. Latency and throughput are the wrong primary signals. The signals that matter are: did the agent take an action, was the action authorized, was it correct, was it reversible, and did a human have an opportunity to intervene. None of those are derivable from p95 latency. Fast wrong is not a metric worth optimizing.
The fourth break is behavioral drift. Chen, Zaharia, and Zou reported that GPT-4's accuracy on a prime-versus-composite identification task fell from 84% in March 2023 to 51% in June 2023, a 33-point drop on the same task, using the same nominal model identifier, with no changes on the user side. No infrastructure alert fired. No error rate changed. The system was, by every operational measure, working correctly. The lesson is not that GPT-4 became generally worse. It is that model behavior can shift materially without an infrastructure signal. This is what drift looks like at the monitoring layer: invisible. The instruments that detect anomalies in metric streams are not calibrated to notice that model behavior on a specific task has quietly shifted. By the time it surfaces, it surfaces in a supplier call, or a compliance audit, or a patient outcome.
The fifth break is blast radius. In April 2026, PocketOS founder Jer Crane reported that a Cursor coding agent, powered by Claude Opus 4.6, used an overly broad Railway API token to delete a Railway volume tied to PocketOS production data and volume-level backups in nine seconds. The destructive call did not require an infrastructure outage. It succeeded through authorized plumbing. By the time a downstream alert would detect missing data or failed operations, the irreversible action had already occurred. The lesson is that agentic systems can execute sequences of irreversible real-world actions faster than monitoring-and-alert cycles are designed to operate. When the unit of failure is an action with external consequences, rather than a request that returns an error code, the monitoring architecture needs to be upstream of the action, not downstream of it.
The SAP Cloud ALM gap, stated precisely
SAP Cloud ALM monitors execution, integration, exceptions, user scenarios, and business-process KPIs. That is already a higher-order operational view than raw infrastructure monitoring. In an S/4HANA extension where an AI agent approves procurement orders, classifies support tickets, or generates financial journal entries, Cloud ALM will tell you the integration flow ran in 230 milliseconds, the BTP function returned 200, and the Source-to-Pay KPIs show no anomaly. It will not tell you whether the agent approved the right purchase order, classified the ticket correctly given the context in the knowledge base, or generated a journal entry that would survive audit. The gap is not a product failure. It is a design-scope boundary. Cloud ALM was designed for systems where many important failures manifest as process, integration, exception, or KPI deviations. Agentic systems introduce a class of failures where the process can complete cleanly while the judgment that initiated it was wrong.
The same boundary exists in Datadog, Dynatrace, and every other enterprise APM platform, including their new LLM observability products. Those products are real. Datadog's AI Agent Monitoring, Dynatrace's execution path visualization, New Relic's quality metrics, OpenTelemetry's GenAI semantic conventions covering agent spans and tool calls: these are genuine advances, not marketing. They extend the monitoring stack meaningfully into the agent execution layer.
They now capture far more than latency and cost: prompts, model calls, tool invocations, retrieval steps, guardrail outcomes, traces, and agent execution paths. But the hardest judgment, whether the action was correct in the business or clinical context, still depends on customer-defined evaluators, policy gates, human review, and often LLM-as-judge workflows. The behavioral layer is often a combination of configurable evaluators, policy checks, human feedback, and sometimes LLM-as-judge. And LLM-as-judge has documented systematic biases: it prefers longer answers, it prefers the answer in the first position, it prefers outputs from the same model family that generated the answer being judged. These are not edge cases in the literature. They are characterizations of the primary measurement instrument every behavioral monitoring product on the market is currently built on.
This is the honest state of agentic observability in mid-2026: the necessary infrastructure monitoring exists and is mature. The behavioral monitoring layer is real and improving, but sits on a measurement instrument with known failure modes, and most teams have not calibrated it against human raters. What is still missing from the public literature is a widely adopted, regulator-aligned reference architecture for behavioral monitoring of agentic systems in production.
When the monitor has the same problem as the monitored
There is a particular irony in where the industry has landed. The behavioral monitoring layer that sits above APM, the LLM-as-judge graders that score agent outputs in production, is itself an AI system. It is subject to drift. It can hallucinate a passing score. It has documented biases that cause it to grade systematically incorrectly in predictable directions. We have addressed the gap in traditional monitoring by adding an AI layer, and that layer carries its own version of every problem we were trying to solve.
This matters beyond the technical critique. The human supervisor reviewing behavioral monitoring alerts faces the same dynamics I have written about in this series in another context: trust builds, and supervision erodes. When the LLM-as-judge fires green consistently for weeks, the person reviewing its outputs starts treating it as reliable. The alert that eventually fires is reviewed quickly, approved, and dismissed. The pattern is not negligence; it is the entirely predictable result of placing a human being in a monitoring loop without designing for how human attention actually works over time.
I wrote in an earlier piece in this series that trust builds naturally and supervision erodes naturally. If the product was not designed to hold oversight stable, the agent ends up at an autonomy level nobody authorized. The same dynamic applies one level up. If the monitoring system is not designed to hold reviewer attention stable, the monitoring layer erodes into a green-light machine that nobody is genuinely reading.
The implication is uncomfortable but direct. AI-assisted monitoring of AI agents is not a solved problem; it is a recursion that requires the same discipline applied twice. The calibration and human review requirements for the monitoring layer are not a nice-to-have. They are load-bearing.
The data layer is the foundation, not the substrate
Every discussion of agentic monitoring eventually surfaces the same question: where does the wrong answer actually come from? And the answer is more often than teams want to admit: from the data the agent was given, not from the model's reasoning.
An agent reasoning over stale pricing data will approve purchase orders that miss market conditions. An agent working from a knowledge base with outdated product policies will give customers guidance the company stopped supporting six months ago. An agent whose knowledge graph has incorrect entity mappings will classify support tickets into the wrong workflows, confidently, every time, with no error signal at the application layer. The model is doing its job. The substrate is wrong. Infrastructure monitoring sees none of it; it is not looking at data quality.
This is why data observability is not a separate concern from agentic observability. It is the foundation. The relevant properties are not abstract: data freshness (is the retrieval layer pulling from current sources?), data completeness (are there gaps that will cause the agent to reason from partial evidence?), referential integrity (do the identifiers the agent uses to connect concepts actually connect to the right things?), context availability (is the context the agent needs to make a correct decision accessible in the form the agent can use it?), and knowledge graph mapping accuracy (are the semantic relationships the agent traverses actually correct?).
Tools like Monte Carlo, Acceldata, and Great Expectations monitor freshness, schema drift, and volume anomalies on data warehouse layers. They were built for analytics pipelines. They do not natively monitor vector index freshness, embedding drift, or whether retrieved document provenance is intact. The data observability stack and the retrieval stack are still largely separate concerns in most enterprise architectures, with no unified surface showing whether the data the agent is reasoning from is trustworthy at the moment it reasons from it.
This gap has a specific name in security research: RAG poisoning. PoisonedRAG reported 90% attack success when injecting five malicious texts per target question into a knowledge base containing millions of texts. The model may be behaving as designed over corrupted evidence. Nothing in the application layer signals a problem.
Trustworthy AI results require trustworthy data. That is not a philosophical position; it is an architectural requirement. The monitoring architecture that does not include the data layer is watching the agent reason while ignoring the quality of what it is reasoning from.
When something goes wrong: attribution is its own discipline
The hardest question in agentic operations is not "did the agent fail?" It is "why did it fail, and at which layer?"
A wrong procurement approval could be a model problem (the reasoning was incorrect given correct inputs), a data problem (the reasoning was correct given incorrect inputs), a context problem (the relevant policy was not available to the agent at decision time), a configuration problem (the agent's autonomy boundary was set incorrectly by someone who misunderstood the use case), or a knowledge graph problem (the entity mapping that connected this vendor to this contract category was wrong). Each of these has a different fix. Conflating them produces the wrong intervention, and in regulated environments, the wrong documentation.
Attribution requires three things that most current deployments do not have.
The first is data lineage: the ability to trace the specific documents, records, and retrieved context that were present in the agent's reasoning window at the moment of the decision. Not what the knowledge base contained in general; what the agent actually saw. Without lineage, you can identify that the output was wrong but cannot determine whether the source material was wrong, incomplete, or simply misapplied.
The second is agent activity logging at the right granularity. Not just that the agent called a tool and received a result, but the sequence of decisions that led to that call, what the agent considered and rejected, and what it treated as authoritative. OpenTelemetry's GenAI semantic conventions for agent spans are moving toward this, covering create_agent, invoke_agent, invoke_workflow, and tool-call spans. What is not yet standardized is the semantic correctness assertion, the blast-radius classification, and the override event. Those remain proprietary to each platform, which means post-incident analysis requires platform-specific forensics rather than a portable audit trail.
The third is decision-trace capture: the ability to reconstruct the evidential path that led to the action, including retrieved sources, tool results, policy checks, confidence signals, rejected options where available, and the final action rationale. This is qualitatively different from a stack trace. A stack trace tells you the program's execution path. Decision-trace capture tells you what the agent retrieved, what it treated as authoritative, what alternatives it considered, and what justified the action it took.
The MedLog proposal, led by Harvard-affiliated researchers with a broad international author group, is the most concrete published attempt to specify what this logging needs to contain for clinical AI: nine fields covering the model, the user, the target, the inputs, the artifacts, the outputs, the outcomes, and the feedback. The structure is explicitly modeled on syslog. The principle generalizes: audit trails for agentic systems need to be designed the way audit trails for clinical AI need to be designed, because both involve autonomous decisions with real-world consequences and a regulatory requirement to know, after the fact, exactly what happened and why.
Attribution is not a forensics tool. It is a design requirement. If the logging is not in place before the incident, the post-incident analysis is reconstruction from fragments. In a system with real-world side effects, that is not acceptable.
What the monitoring architecture actually needs
The six instruments I have written about in this series map directly to what the traditional stack cannot provide. Task success rate requires semantic validation against a ground truth, not HTTP status. Unintended action rate requires classifying every tool call with side effects against a policy specification, not a throughput metric. Override frequency is a signal that comes from human interruptions and manual takeovers, not from error logs. Confidence calibration requires tracking whether the agent's expressed certainty matches its empirical accuracy over time. Rollback time is a first-class SLO for any agent with real-world side effects. Incident recovery time requires knowing not just that something failed, but that the compensating action was taken and validated.
The emerging architecture is a continuous loop: pre-deployment evals, production tracing, behavioral drift detection, human override capture, re-evaluation, policy update. This is the same epistemology the ICU uses. Instruments tell you what the system is doing. Clinical judgment tells you whether it is well. The loop is the product, not an add-on.
For teams in healthcare and other regulated environments, this is not a best-practice question. The FDA's December 2024 guidance on Predetermined Change Control Plans requires real-world performance monitoring as part of any modification protocol for continuously learning AI. ONC's Decision Support Interventions rule requires intervention risk management practices covering validity, reliability, robustness, and safety. A 2025 position paper, citing a recent review, reports that only 9% of FDA-registered AI-based healthcare tools include a post-deployment surveillance plan. The gap between what the monitoring infrastructure shows and what the regulatory framework requires is not being closed by adding a Grafana dashboard.
The question to ask your vendor
The question is not "do you have AI observability?" Every major vendor says yes. The questions are: show me the calibration data for your behavioral grader against expert human review on my use cases. Show me your action-policy gate latency. Show me override-rate baselines for the last 30 days. Show me the rollback infrastructure and what happens when the agent needs to be reversed. Show me how your monitoring maps to what the regulator will ask for.
If the vendor cannot answer those questions, the gap is theirs. And yours.
The monitors tell you what the system is doing. The harder discipline is knowing what the monitors cannot see. I learned that before I ever wrote a line of product specification, in a room with continuous waveforms and a patient who needed more than green numbers on a wall.
The operating room taught me that attention and instrumentation are not the same thing.
We are building systems that act in the world. We owe them the right instruments.
This article is part of an ongoing series on AI product design, healthcare data, and the human side of technology adoption.
Sources
- Mehta, A. (2026). "When Agents Disagree With Themselves: Measuring Behavioral Consistency in LLM-Based Agents." arXiv:2602.11619.
- Chen, L., Zaharia, M., & Zou, J. (2023). "How is ChatGPT's behavior changing over time?" arXiv:2307.09009.
- D'Amour, A. et al. (2022). "Underspecification Presents Challenges for Credibility in Modern Machine Learning." JMLR 23(226).
- Subbaswamy, A., & Saria, S. (2020). "From development to deployment: dataset shift, causality, and shift-stable models in health AI." Biostatistics 21(2).
- Finlayson, S.G. et al. (2021). "The Clinician and Dataset Shift in Artificial Intelligence." NEJM 385(3).
- Zheng, L. et al. (2023). "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena." NeurIPS 2023. arXiv:2306.05685.
- Pan, M.Z. et al. (2025). "Measuring Agents in Production." arXiv:2512.04123.
- Noori, M. et al. (2025). "A global log for medical AI." arXiv:2510.04033. (Preprint, Harvard Medical School / Harvard DBMI)
- Moffatt v. Air Canada, 2024 BCCRT 149.
- Cursor / PocketOS incident (2026). CX Today; TechRadar; Railway.app incident reports.
- FDA. "Marketing Submission Recommendations for a Predetermined Change Control Plan for Artificial Intelligence-Enabled Device Software Functions." December 4, 2024.
- ONC. Decision Support Interventions, 45 CFR §170.315(b)(11). Effective March 11, 2024.
- SAP Cloud ALM Synthetic User Monitoring documentation. SAP Help Portal.
- Datadog. "AI Agent Monitoring." DASH 2025 press release, June 10, 2025.
- Zou, Y. et al. (2025). "PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation." USENIX Security 2025.
- OpenTelemetry GenAI Semantic Conventions, v1.37+. GenAI SIG, April 2024 onwards.
- Dolin, R. et al. (2025). "Statistically Valid Post-Deployment Monitoring Should Be Standard for AI-Based Digital Health." arXiv:2506.05701. NeurIPS 2025 Position Paper Track.
- Crane, J. (2026). PocketOS incident report. runcycles.io/blog/ai-agent-deleted-prod-database-9-seconds.


