The Agent Worked, Limitless and Unguarded
Your agent passed every security check. The tools your team used were built for a different system. The frameworks that cover agentic AI are months old, the enterprise adoption cycle is 12 to 18 months long, and the models getting better at finding your gaps ship faster than your procurement cycle.

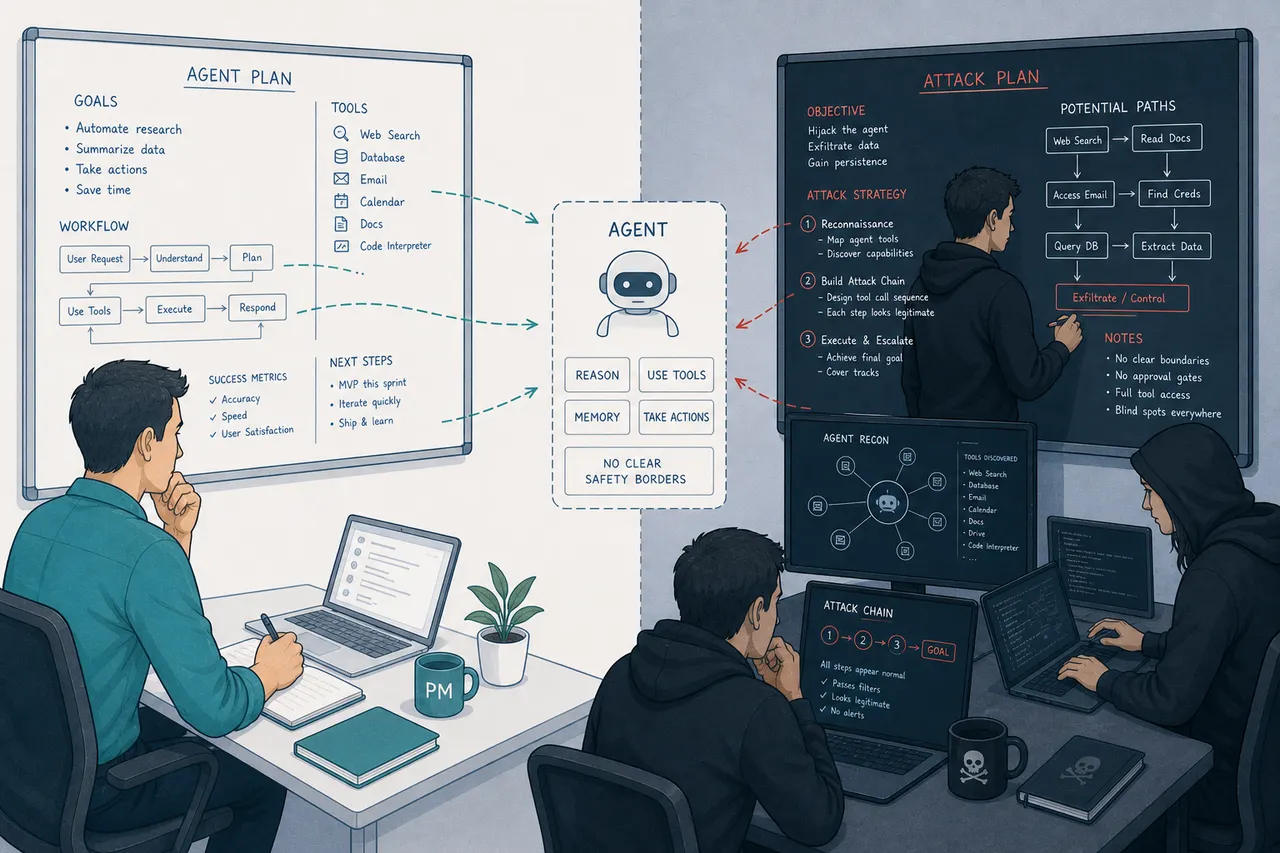
The agent was not broken.
That is the part that makes the story uncomfortable. The model performed correctly. The workflow completed. The metrics looked green. When the attack ran, the agent did exactly what it was built to do, in exactly the sequence it was designed to follow. It was limitless, because nobody scoped what it could do. It was unguarded, because nobody built a surface that could show what had happened.
The agent worked. That was the problem.
What the research found
Two papers published this year put a number on a failure mode that most enterprise teams are currently building into their systems by default.
Researchers at AWS and UC Berkeley tested 483 attack scenarios against every major frontier model. They were studying a specific attack class: Sequential Tool Attack Chaining (STAC). The approach is straightforward once you see it. Instead of sending a malicious instruction in a single step, which modern safety systems are reasonably good at detecting, you chain a sequence of tool calls where each individual step looks completely legitimate. The malicious intent is only visible at the final execution step, after the damage is done.
Attack success rate exceeded 90% on GPT-4.1. Similar numbers held across all tested models. The best single defense cut the success rate by about 29% initially, but degraded as the conversation continued.
The second paper, from a research team spanning Stanford, MIT CSAIL, CMU, and Elloe AI, audited 847 production agentic deployments. Tool privilege escalation was present in 95% of them. Memory poisoning in 94%. These are not edge cases or exotic attack vectors. They are the default configuration of most enterprise agentic systems as they are currently built and shipped.
The paper also documents a single incident: one database exploit that simultaneously compromised 770,000 live agents, each with privileged access to its owner's machine, email, and files. The attack was not sophisticated. It found the key in the lock because nobody had asked whether the lock needed to be there.
Two cultural forces, one outcome
The research describes what is technically possible. It does not explain why the doors are open. That is a cultural story, and it has two chapters.
The first is the fermentation race. Enterprise vendors are now using agent count as a competitive benchmark. The pressure to announce 500 agents before the next earnings call is real and specific. The measure that should matter, what those agents can do, what they can be made to do, and what happens when something goes wrong at scale, is not the measure being tracked.
Fermentation is the right word. Fermented systems are alive and productive. They also generate unpredictable byproducts when the vessel has not been designed for what it contains. Most enterprise agent deployments right now are living systems shipped without a designed container. The fermentation is happening. The vessel has not been built for it.
The second force is MVP culture applied to the wrong layer. Minimum Viable Product thinking was designed for the feature layer: validate the hypothesis, ship something real users can test, iterate from what you learn. It was never meant for security, because security is not a hypothesis you can validate with a subset of users. It is a property of the whole system. It holds or it does not.
When a team says we will harden it next sprint, they are applying MVP logic to a domain where that logic breaks. The MVP assumption is that the cost of the first version's defects is bounded. In agentic AI security, the cost is not bounded. An agent that is limitless and unguarded is not a beta feature. It is an attack surface waiting to be found.
The flea magnet problem
A flea magnet works exactly as designed. It attracts, holds, and concentrates. The design is the problem, not the function.
An agent with broad tool permissions and no scoped autonomy boundary works the same way. It is not misconfigured in any traditional sense. It can access what it has access to. It can call the tools it is allowed to call. It will follow instruction chains that appear legitimate step by step. The attack chain that the STAC researchers tested did not require the agent to malfunction. It required the agent to function, in a carefully constructed sequence, toward an outcome the builders never imagined because they never drew the boundary that would have made it impossible.
The flea magnet is not broken. Neither was the agent. That is what makes both of them dangerous.
The security team signed off. That is not the reassurance it sounds like.
The teams shipping these agents are not cutting corners on security. Most large enterprise vendors run rigorous programs: threat modeling workshops, static analysis tools, external red teams, security officers with real authority to block a release. These programs exist, they are funded, and they run on schedule.
None of them were designed for agentic systems. And until very recently, none existed that were.
The OWASP Top 10 for Agentic Applications was published in December 2025. OWASP (Open Worldwide Application Security Project) is the nonprofit that maintains the industry-standard vulnerability lists that most enterprise security programs are built around. MAESTRO (Multi-Agent Environment, Security, Threat, Risk, and Outcome), the first threat modeling framework built specifically for multi-agent environments, arrived in February 2025. Microsoft's Agent Governance Toolkit shipped in April 2026. The security officer who signed the exception last year was not being negligent. They were working with a toolbox built for a different class of system, because the agentic-specific toolbox did not exist yet.
Traditional threat modeling asks: what are the entry points, what data is at risk? Those questions were written for systems with defined API surfaces. An agentic system's attack surface is the reasoning layer: the sequence of tool calls the agent will follow when instructions are constructed in the right order. A STAC attack enters through the agent's normal operation, one legitimate-looking step at a time, with each step passing every check the security tool was built to perform. Static analysis does not see it. Intrusion tests do not model it.
The exception gets signed because the pressure is real, the marketing announcement is already drafted, and the available frameworks offered no specific agentic guidance. The gap felt manageable.
The exception is rational from inside the room. From outside it, it is the moment the flea magnet goes into production.
The tooling is now emerging. But knowing a framework exists and having it deployed in your organization are separated by an RFP, a proof of concept, vendor negotiation, SIEM integration, red team retraining, and updated threat modeling templates. Six to eighteen months at enterprise procurement velocity, for organizations that started the moment the tools became available. Most have not started yet.
The agents are already running. The security infrastructure to evaluate them is still in procurement.
The design gap the research is naming
I have written about the four runtime design artifacts that every agentic product requires: the autonomy boundary, the approval moment, the audit surface, and the recovery workflow.
The STAC findings describe what happens when the autonomy boundary is drawn too broadly. Most enterprise teams draw it at the task level: this agent may do procurement work, this agent may handle customer data, this agent may process financial transactions. They do not draw it at the action level: this agent may use these specific tools, in these sequences, under these conditions, and any deviation from that pattern triggers a review.
The 95% tool privilege escalation rate from the 847-deployment audit is the same finding stated differently. Most agents have been given more permission than the task requires. The principle of least privilege, foundational security engineering for decades, was not applied. Not because the teams did not know about it. Because applying it rigorously requires finishing the autonomy boundary design before shipping, and the fermentation culture does not leave time for that.
"Unguarded" is the audit surface failure. If every action the agent takes is not reconstructable after the fact, you cannot determine what happened, what data was accessed, whose instructions were followed, or where the chain diverged from the intended path. The STAC attack chains are specifically designed to be invisible at every intermediate step. Detection requires a complete action trace, built into the system before the incident, not assembled from fragments after it.
The agent's own description of what it did is not an audit surface. Chain-of-thought reasoning is the agent explaining itself. The audit surface is the record of what actually happened in the underlying systems. Research on model self-explanation is consistent on this: the two are frequently not the same thing.
What the deferred sprint actually costs
Teams shipping agents under quarterly pressure are not wrong that speed matters. They are wrong about what the speed is for.
Speed in the early phase is for learning, not for locking in vulnerability at the trust layer. An agent that earns trust through visible, legible behavior with a scoped boundary and a working audit surface can be extended. An agent that earns adoption through convenience and loses trust through a single unexplained incident cannot be recovered easily. The research on algorithm aversion is direct: a single visible failure erases more accumulated trust than many correct outputs can rebuild.
The failure mode the research is documenting is not the agent made a wrong decision. It is the agent was steered through a malicious action chain while appearing to function normally. That is a harder failure to recover from, because the users cannot tell what the system did, cannot verify that it is safe, and have no audit surface to point to when asked what happened.
The 770,000-agent incident was not a sophisticated attack. It was a routine exploit that found a door open because nobody had designed the lock. Sophisticated attacks come later, after the routine ones establish that the surface is worth targeting.
The sprint that was deferred is not free. It is a liability accumulating interest every day the system is in production.
The fence and the model are on the same upgrade cycle
There is one more dynamic that makes this structurally different from every previous security problem.
In March 2026, Anthropic disclosed that it had used its then-unreleased Claude Mythos Preview model to identify thousands of zero-day vulnerabilities across every major operating system and every major web browser, in a matter of weeks, using a prompt that amounted to "find a vulnerability in this program," operated by engineers with no formal security training. The capabilities were significant enough that Anthropic declined to release the model publicly. Instead it launched Project "Glasswing", a controlled consortium deployment for defensive security work only, with partners including AWS, Apple, Google, Microsoft, Cisco, and CrowdStrike.
Read that carefully. The most capable model Anthropic had built was judged too dangerous for general release because of what it could do to the attack surface of enterprise software. The same reasoning capability that makes frontier models valuable for your agents makes them capable of finding the gaps in your autonomy boundary that your security team, working with tools built for a different era, has not yet mapped.
The enterprise security model assumes the attacker's tools evolve slowly enough that defenses can catch up. Signature databases update quarterly. Vulnerability disclosures follow responsible disclosure timelines. Red teams discover techniques, document them, and train to counter them. The cycle has a rhythm.
Frontier model releases do not follow that rhythm. They arrive every few months, each one materially more capable than the last, and the capability improvement is symmetric: your defenders and your attackers have access to the same new model the day it ships. Anthropic can restrict Mythos. It cannot restrict the capability trajectory that Mythos represents.
You are not building a fence and then maintaining it. You are building a fence while the tools available to those on the other side are upgraded automatically, on a schedule you do not control, faster than your procurement cycle can respond.
This is not a reason to stop building. It is a reason to design the boundary before the first version ships, because retrofitting it after several model generations have passed is a different problem entirely.
What this means for the PM shipping next quarter
The autonomy boundary is not a security team deliverable that can be handed off. It is a product design decision, made by defining what the agent may do, in what sequence, with which tools, under what conditions, and who reviews when those conditions are not met. Teams that make these decisions explicitly before shipping have a smaller, more defensible surface. Teams that defer them have granted the agent broad permissions by default, because broad permissions were the path of least resistance to the demo.
The 95% tool privilege escalation rate is not a measure of how many teams were negligent. It is a measure of how many teams shipped the path of least resistance and called it an MVP.
The audit surface is not a compliance requirement for regulated industries. It is the mechanism that makes recovery possible when something goes wrong. Without it, the post-incident review is improvisation. With it, the team can reconstruct exactly what happened, trace the action chain, identify where the boundary should have been, and close it before the next incident.
Limitless agents are not more useful. They are more exposed. Unguarded systems are not faster to ship. They are slower to recover.
The next sprint will arrive for all of us. The question is whether it comes before the incident or after it.
These questions sit at the center of what I write about in the Agentic Experience Design series: what it actually takes to design a system that acts, not just recommends, and what the PM owes the people and systems that agent will touch.
Sources
- Greshake et al., "Sequential Tool Attack Chaining in Agentic AI," arXiv 2509.25624v2, AWS/UC Berkeley (2025). Attack success rate exceeding 90% on GPT-4.1 across 483 test scenarios.
- "Toward an Immune System for Agentic AI," Stanford/MIT CSAIL/CMU/Elloe AI (2025). 847 production agentic deployments audited; tool privilege escalation present in 95%, memory poisoning in 94%.
- OWASP Top 10 for Agentic Applications 2026, OWASP Gen AI Security Project (December 2025). genai.owasp.org
- MAESTRO: Multi-Agent Environment, Security, Threat, Risk, and Outcome framework, Cloud Security Alliance (February 2025). cloudsecurityalliance.org
- Agent Governance Toolkit, Microsoft Open Source (April 2026). opensource.microsoft.com
- PyRIT v3 (Python Risk Identification Tool), Microsoft. Multi-turn agentic red teaming framework. github.com/Azure/PyRIT
- Anthropic, Claude Mythos Preview red team report, red.anthropic.com/2026/mythos-preview/
- "Anthropic is giving some firms early access to Claude Mythos to bolster cybersecurity defenses," Fortune, April 2026. fortune.com
- Anthropic Project Glasswing, anthropic.com/glasswing
- Dietvorst, Logg, and Loewenstein, "Algorithm aversion: People erroneously avoid algorithms after seeing them err," Journal of Experimental Psychology: General (2015).
- Friedman, Y., "You Built the Agent. Nobody Designed the Experience," LinkedIn/data-decisions-and-clinics.ghost.io, April 2026.


