What Makes a Doctor a Doctor
A new BMJ paper asks why humans are still in the loop now that AI outperforms physicians on reasoning tasks. The answer is a framework. The problem is that framework assumes a physician whose independent competence AI is quietly eroding.

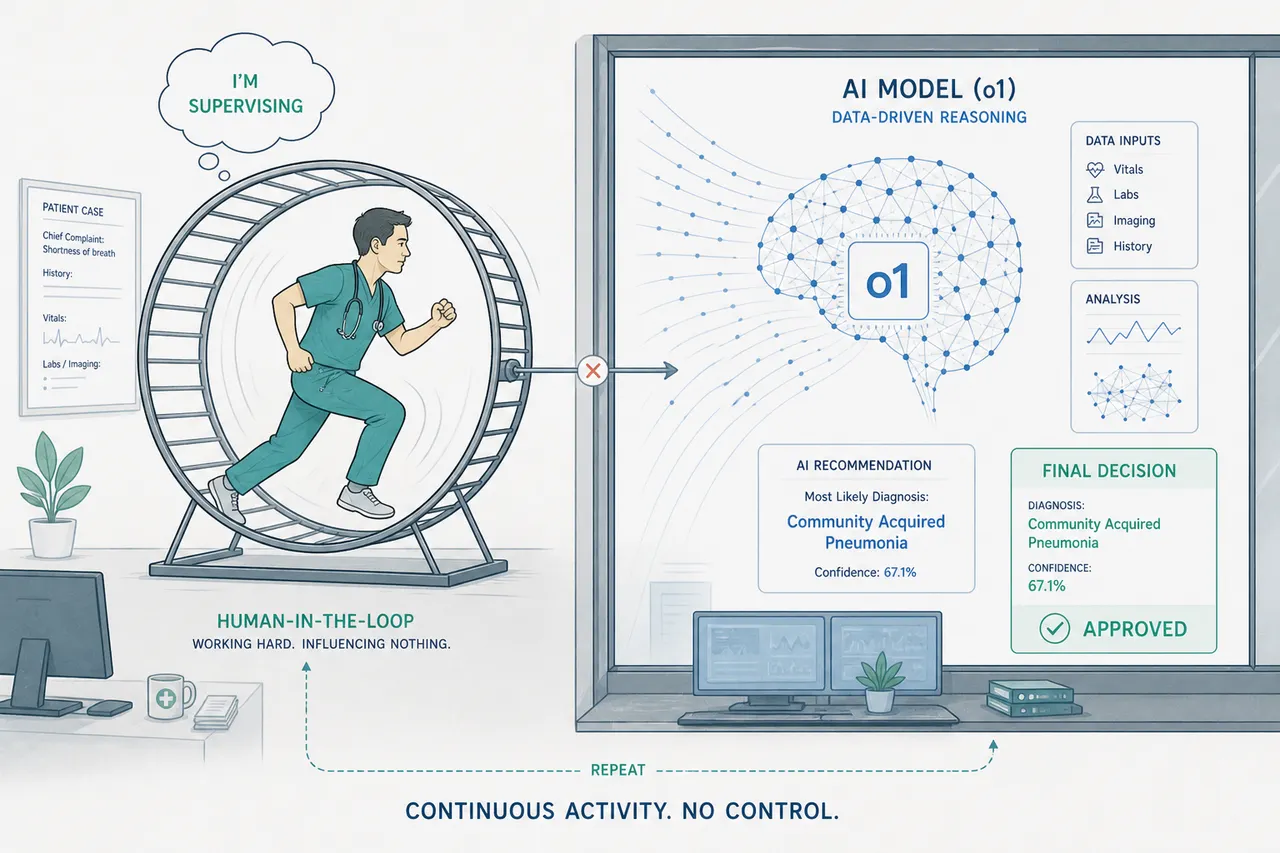
A new paper in BMJ Digital Health asks a question that would have seemed absurd five years ago: now that AI is starting to outperform physicians on clinical reasoning tasks, why are humans still in the loop at all?
The authors, Chen, Pfeffer, and Longhurst from Stanford and UCSD, are not asking rhetorically. They mean it seriously. And their answer, carefully constructed around three qualities they call the 3C framework, is worth reading closely, not just for what it gets right, but for the uncomfortable problem it quietly surfaces in its own argument.
The paper opens by acknowledging what most people in healthcare AI are still reluctant to say plainly. AI systems alone can now outperform humans who have access to those same AI systems on complex medical reasoning tasks. Not just on rote retrieval, not just on pattern matching in imaging, but on the kind of multi-step clinical reasoning that physician licensing exams were designed to isolate. The fundamental theorem of biomedical informatics, that human plus computer will always outperform either alone, is starting to look like an artifact of a particular moment in AI capability rather than a durable truth.
So what is left? What does a physician actually provide that a sufficiently capable AI cannot?
The authors answer with three qualities, each organized as a progression from a weaker to a stronger claim.
Competence moves from knowledge to judgment. Knowledge is what AI increasingly has in abundance. Judgment is what it lacks. In my radiology training, reading a chest film was never really about identifying the finding. Any textbook could teach you the finding. The hard part was deciding what it meant for this patient, on this day, given everything else you knew about them. A ground-glass opacity in a 35-year-old nonsmoker presenting acutely means something entirely different than the same finding in a 70-year-old who has been coughing for six months. The image is identical. The judgment is not. The authors put it precisely: whether to continue blood thinners in a patient with both a heart condition and a stomach ulcer is not a question of facts. It is a question of values, and values are what humans provide.
Communication moves from empathy to influence. The authors make a useful distinction here. Empathy, they argue, is a weak moat. It can be offered by many non-physician humans, and it can be simulated by AI. What matters is influence: the ability to actually change what happens. I spent time in anesthesiology, a specialty where the patient is unconscious for most of the encounter. The communication that matters happens before and after, negotiating with surgeons about risk, with patients about fear, with families about expectations. Knowing the right answer is necessary but not sufficient if no one acts on it. That capacity to move people, not just inform them, is not a feature of knowledge. It is built through years of difficult conversations with real consequences.
Character moves from liability to responsibility. This is the deepest claim in the paper, and the one that resonates most with me as a physician. A trustworthy clinician does not merely assume legal liability for outcomes. They take genuine professional responsibility for them. The distinction matters because liability is a formal relationship that can in principle be assigned to any entity, including an AI system or its developer. Responsibility is something different. It requires the capacity to understand what you are taking responsibility for, to communicate authentically enough to be trusted, and to own outcomes that were not what you intended. The scientific community has largely converged on not accepting AI authorship on papers not because AI cannot write, but because it cannot be held accountable for what it writes. A physician who signs off on an AI recommendation carries that accountability. The question is whether the signing is genuine or ceremonial.
This is a coherent and well-argued framework. It is also, if you follow it to its conclusion, more unsettling than the authors perhaps intend.
The 3C framework describes what a physician is supposed to provide. It does not address the question of whether a physician who has been using AI routinely for months or years is still in a position to provide it.
This is where I find myself thinking less like a physician and more like a product manager who has spent years building AI systems and watching how people actually use them. When you ship an AI product into a clinical workflow, you are not just adding a capability. You are changing what the human in that workflow practices every day. And what people stop practicing, they stop being good at. That is not a philosophical concern. It is an adoption and design problem, and it is one most teams building clinical AI are not treating seriously.
Judgment, the move from knowledge to something more, requires independent competence as its foundation. A clinician who cannot evaluate a recommendation independently, who has not been practicing the diagnostic reasoning that AI now performs for them, cannot exercise genuine judgment on an AI output. They can approve it or reject it, but approval without understanding is not judgment. It is a rubber stamp with a medical degree. I have seen this dynamic in enterprise AI deployments outside healthcare: the moment a system becomes reliable enough to trust by default, the humans in the loop stop stress-testing it. Not out of laziness, but because the workflow no longer creates the conditions for independent verification.
Influence, the move from empathy to the ability to actually change outcomes, requires clinical authority. That authority rests on demonstrated expertise. A physician whose diagnostic reasoning has atrophied through disuse has a weaker claim to that authority than they once did, even if the credential remains valid. Patients sense this. Colleagues sense it. The social contract of the physician-patient relationship is built on the assumption that the person across from you has genuinely reasoned through your situation, not reviewed a system's output and signed their name to it.
Responsibility is the most fragile of the three. To genuinely take ownership of an outcome, you need to have been genuinely engaged in producing it. A clinician who reviewed an AI recommendation for thirty seconds before signing off has assumed liability. They have not taken responsibility in the sense the authors mean. The distinction between those two things is precisely what the AI supervisory fallacy obscures. And as a product manager, I know that thirty-second review is exactly what happens when you design a workflow that optimizes for throughput and treats the human approval step as a checkpoint rather than a cognitive act.
The authors name the supervisory fallacy directly: the false assumption that humans are willing or able to effectively double-check the work of computer systems. They flag it as an uncomfortable question. What they do not fully pursue is that the 3C framework, as they define it, assumes a physician whose competence, communication capacity, and character were forged through years of independent practice, and that those qualities are maintained through continued exercise of that independence.
If the AI does the reasoning, the physician does not practice reasoning. If the physician does not practice reasoning, the qualities the 3C framework depends on begin to erode. The framework describes what physicians bring to the table. It does not account for what happens to those qualities when the work that produced them is systematically offloaded. That gap is not the paper's failure. It is the field's next problem.
None of this is an argument against AI in clinical medicine. The authors are right that routine healthcare transactions, titrating a blood pressure medication, treating an uncomplicated urinary infection, could and perhaps should be redirected to AI-driven care. The question is what happens to the physicians who remain in the loop for the complex cases, after years of watching AI handle the cases that once kept their reasoning sharp.
Aviation has a name for this. Pilots who supervise reliable automation for long periods become measurably worse at manual flight when the automation fails. The solution was not to remove the automation or to trust that awareness of the problem would be sufficient. It was structural: mandatory no-automation proficiency requirements, recurring simulator scenarios, compulsory practice without the crutch.
Medicine does not yet have an equivalent. The 3C framework tells us what we need physicians to be. It does not tell us how to ensure they remain that way in a world where AI handles more of the cognitive work that made them who they are.
That is the harder question. And it is the one the paper, understandably for an editorial, leaves at the door.
This article is part of an ongoing series on healthcare AI, clinical workflow, and the systems that connect them.
Sources
- Chen JH, Pfeffer MA, Longhurst CA. Why are humans still in the loop with advancing AI capabilities? BMJ Digital Health & AI. 2026;2:e000057. https://doi.org/10.1136/bmjdh-2026-000057
- Tu T, Schaekermann M, Palepu A, et al. Towards conversational diagnostic artificial intelligence. Nature. 2025;642:442–450.
- Goh E, Gallo RJ, Strong E, et al. GPT-4 assistance for improvement of physician performance on patient care tasks: a randomized controlled trial. Nature Medicine. 2025;31:1233–1238.
- Friedman CP. A "fundamental theorem" of biomedical informatics. Journal of the American Medical Informatics Association. 2009;16:169–170.


