The Study That Finally Earns the Conclusion
Most AI clinical studies measured the wrong thing. They constrained the reasoning mechanism and then evaluated what was left. The Brodeur Science paper finally tests the model the way medicine actually works. The results are hard to dismiss.

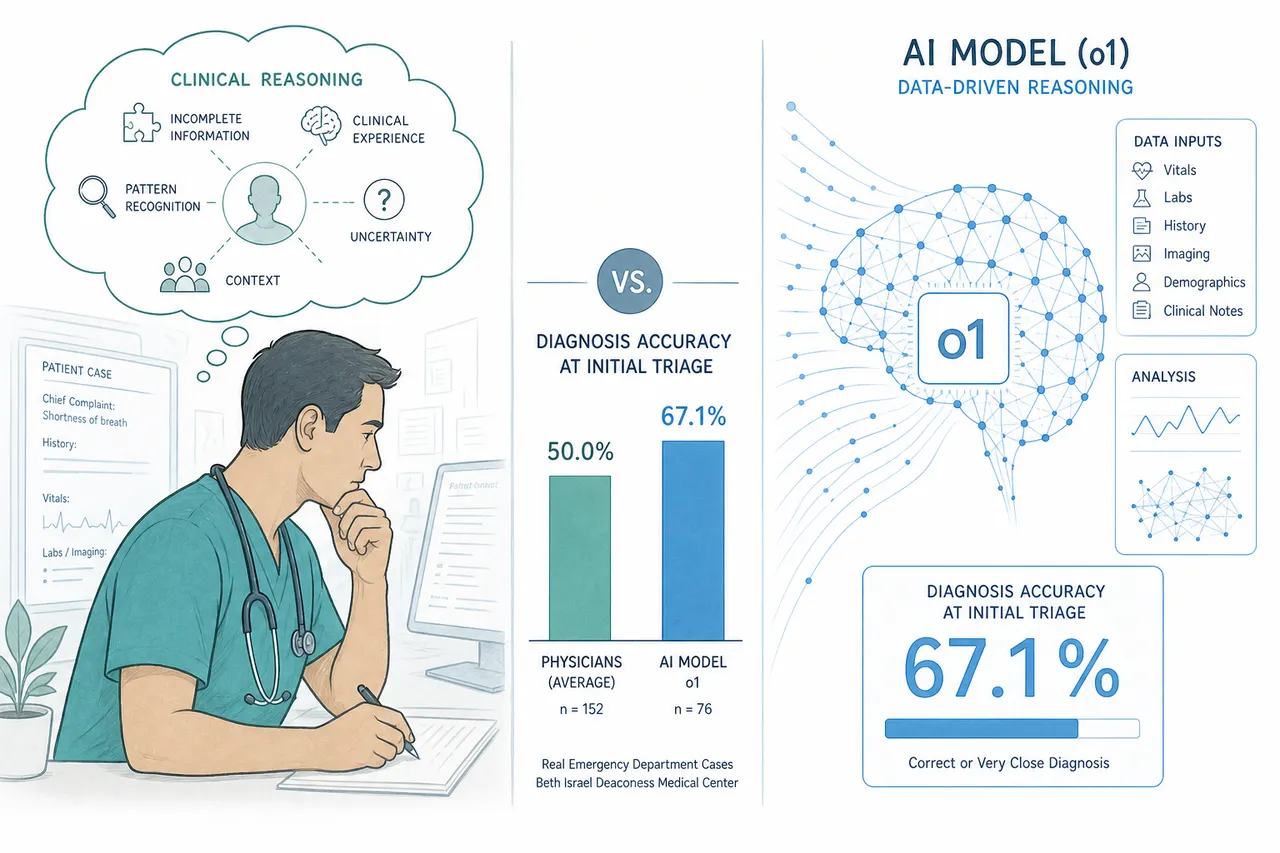
I have read more articles on AI and clinical reasoning in the past year than I read during my entire medical training. NEJM, JAMA, Nature Medicine, Science. Some I have written about here, because the findings were strong enough to deserve more than a press release summary and careful enough to hold up under a methodology read. Most painted a mixed picture: impressive on curated benchmarks, disappointing when real patients and real data entered the room. This week's paper in Science is different. Not because the conclusion is more favorable, but because the experiment finally earns the conclusion.
Brodeur et al., published in Science on April 25, 2026, tested OpenAI's o1 model against physicians across five experiments covering diagnostic reasoning, management reasoning, and clinical knowledge, plus a real-world emergency department study. The ED arm is the one that will get attention. It deserves it.
Seventy-six real patients.
Real emergency room presentations at Beth Israel Deaconess Medical Center in Boston, pulled directly from the health record, evaluated at three clinical touchpoints: initial triage, physician evaluation, and admission. Not structured case summaries cleaned up for a benchmark. Not vignettes written by clinicians for teaching purposes.
At initial triage, where there is the least information and the most urgency to get the direction right, the model identified the correct or very close diagnosis in 67.1% of cases. Two attending internal medicine physicians, blinded to whether each differential came from a human or an AI, scored 55.3% and 50.0%.
The blinding held. One evaluating physician correctly identified the source only 15.2% of the time. The other, 3.1%.
I trained as a physician and spent time in the ER and ICU. I know what initial triage looks like, the noise, the incomplete information, the pressure to commit to a direction before the picture is clear. The idea that a model is doing that better than attending physicians, on real unstructured cases, is not something I dismiss lightly.
Why this study is different from what came before.
Most prior studies of AI clinical reasoning share a design feature that this paper does not: they constrained the reasoning mechanism and then measured what was left.
A Nature Medicine study found ChatGPT under-triaged 52% of real emergencies. That study used clinician-authored vignettes: carefully written, educationally structured, stripped of the ambiguity that characterizes real clinical presentations. The AI was given a forced choice. It could not ask clarifying questions. It answered in a single turn.
A subsequent replication study changed one variable. Under the same forced-choice conditions, frontier models scored 0 to 24% on accuracy. Under free-text conditions, where the model could reason in its own words, three of five models reached 100%. Same models. Same clinical scenarios. What those studies measured was not AI clinical capability. They measured what happens when you remove the reasoning mechanism from a reasoning model and then evaluate the result.
The Brodeur paper's emergency department experiment did not do that. The model received unstructured clinical data and produced a free-text differential, the same format a consulting physician would use. The evaluation was blind. The comparison was two real attending physicians doing the same task under the same conditions.
That is a different kind of evidence. It does not answer every question. But it answers the question most prior studies could not: does this hold when the conditions approximate actual clinical practice? At initial triage, it does.
The finding nobody is writing about.
The emergency department result will get the coverage. The management reasoning finding deserves equal attention and will get almost none.
The paper included a management reasoning experiment using Grey Matters cases, five clinical vignettes developed and scored by 25 physician experts, each followed by questions about next steps in management. o1 scored a median of 89%. For context: physicians with access to GPT-4 scored a median of 41%. Physicians with access only to conventional resources scored a median of 34%.
A 55-point gap. Not a modest improvement over baseline. A different category of performance.
Diagnosis gets the attention because it is the dramatic moment, the detective work that medicine romanticizes. Management is where most clinical harm occurs. The wrong antibiotic. The missed indication for early intervention. The discharge that should have been an admission. The decision to wait rather than act. Management reasoning is the harder problem because it requires integrating diagnosis with patient context, available resources, risk tolerance, and clinical trajectory simultaneously. It is the part of medicine that resists protocol, resists flowchart, and for that reason has always been the hardest to teach and the hardest to evaluate.
A 55-point gap between the o1 model and physicians with conventional resources on management reasoning is not a finding about diagnosis. It is a finding about clinical judgment. If it holds in prospective trials, it is a larger result than the triage number.
The name on the author list worth noting.
Eric Horvitz is a co-author on this paper. He is Microsoft's Chief Scientific Officer, a pioneer in probabilistic reasoning and human-AI interaction, and one of the longest-standing advocates for rigorous human-baseline evaluation of AI clinical decision support. In 1999, he published foundational work on attention-sensitive alerting: the argument that whether to interrupt a human should balance the cost of interrupting now against the cost of waiting. That framework is the theoretical basis for everything we know about alarm fatigue in clinical monitoring.
His presence on this paper is not incidental. The Brodeur study is, in part, the fulfillment of an evaluation agenda Horvitz has been advancing for more than two decades: stop comparing AI to educational benchmarks, start comparing it to physicians doing the same work under the same conditions.
That half of the agenda is now largely complete. The other half, how you present AI clinical output in workflow without creating the alarm fatigue and automation bias that Horvitz also predicted, is not in this paper. It has not been built into most deployed clinical AI products. It is the design problem the field has not yet taken seriously.
What the paper does not answer, and why that matters.
The authors close with a call for prospective trials and investment in clinician-AI interaction design. Both are the right conclusion, and the ordering is deliberate. Prospective trials come first because the remaining question is not diagnostic accuracy. It is outcomes. Did the patient do better? When the AI produced a better differential than the attending physician and the attending followed it, did that change result in benefit?
That data does not yet exist at scale. The capability case is strong enough now that the absence of outcome data is the field's most important gap, not a reason to wait.
The second conclusion, clinician-AI interaction design, is where the work has barely started. When an AI produces a better differential than the physician, how does the physician know that? How does the system surface that disagreement in a way that invites reflection rather than triggering the automation bias or algorithm aversion that Horvitz's own research predicted? How do you build the workflow that makes the capability real rather than theoretical?
Building that is not a research problem. It is a product design problem. The Brodeur paper closes the capability question far enough to make it urgent. Most teams building clinical AI products are not treating it that way.
The framing has shifted, whether or not the field has caught up to that shift. The question is no longer whether AI can reason as well as a physician. On these tasks, under these conditions, it sometimes reasons better. The design challenge is now about deference: how do you build workflows and interfaces that shift reliance toward whichever agent is more likely to be right on this case, without collapsing into blind automation on one side or reflexive rejection on the other? That is a harder problem than capability. It does not yet have a serious research agenda, let alone a product answer.
This article is part of an ongoing series on healthcare AI, clinical workflow, and the systems that connect them.
Sources
- Brodeur PG, Buckley TA, Kanjee Z, et al. Performance of a large language model on the reasoning tasks of a physician. Science. 2026;392(6797):524–527. https://www.science.org/doi/10.1126/science.adz4433
- Kanjee Z, Crowe B, Rodman A. Using large language models to automate the collection and summarization of clinical notes. JAMA. 2023;330:78–80.
- McDuff D, et al. Towards accurate differential diagnosis with large language models. Nature. 2025;642:451–457.
- Johri S, et al. Testing the limits of language models for clinical reasoning. Nat Med. 2025;31:77–86.
- Horvitz EJ. Principles of mixed-initiative user interfaces. CHI 1999 Proceedings. ACM, 1999.


